Server 06 - Redis 개념
in Web-Programming on Server
Redis란 무엇인가?
Server 05 - NoSQL에서 언급한 NoSQL 기술을 기반으로 많은 DB 프로그램들이 쓰이고 있다. 이 중 Redis에 대해서 알아본다.
Redis는 REmote DIctionary Storage의 약자로 모든 데이터를 메모리에 저장하고 조회하는 in-memory DB, 모든 데이터를 메모리로 불러와서 처리하는 메모리 기반의 key-value 구조의 NoSQL 데이터 관리 시스템이다.
Redis 특징
메모리 기반: 데이터를 메모리에 저장하기 때문에 매우 빠른 속도를 제공하며, 특히 실시간 데이터 처리에 적합하다.
다양한 데이터 구조: 단순한 문자열 외에도 리스트(List), 셋(Set), 해시(Hash), 정렬된 셋(Sorted Set) 같은 여러 복잡한 데이터 구조를 지원한다.
영속성 지원: 기본적으로 메모리 기반이지만, 데이터를 디스크에 저장하여 서버가 재시작되더라도 데이터를 복구할 수 있다.
분산 처리: 클러스터링을 통해 여러 서버에 데이터를 분산시켜 대용량 트래픽을 효율적으로 처리할 수 있다.
다양한 용도: 주로 캐시, 세션 저장소, 실시간 채팅 시스템, 리더보드 관리, 메시지 큐 등으로 활용된다.
여기서 가장 주목할 점은 다양한 데이터 구조 부분이다. 버전이 올라가면서 String, List, Set, Hash, Sorted Set외 Geospatial Index, Hyperloglog, Stream 등의 자료형도 지원하고 있다. 여러 데이터 형식을 지원함에 따라 개발의 편의성과 난이도를 줄여주는 역할을 맡고 있다. 어떤 Value를 조회할 때 SQL로 RDBMS 조회하는 것보다, Redis가 제공하는 형태로 찾는 것이 빠르다. 그 때문에 개발자 입장에서 비즈니스 로직에 더욱 집중할 수 있다는 장점이 존재한다. (출처: https://meetup.nhncloud.com/posts/224)
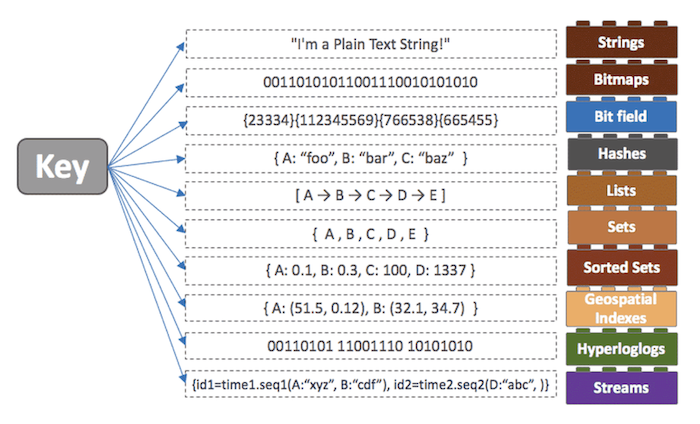
Redis의 CRUD 처리
Redis에서의 CRUD(Create, Read, Update, Delete) 작업은 매우 직관적이며, 명령어 기반으로 처리된다. Redis는 Key-Value 저장소이므로, 기본적으로 키와 값을 조작하는 방식으로 CRUD 작업이 이루어진다.
- Create - SET 명령어
SET key value - READ - GET 명령어
GET key - UPDATE - SET 명령어 (덮어쓰기와 유사)
SET key value - DELETE - DEL 명령어
DEL key
위와 같이 키-벨류로 기본적인 명령어로 CRUD를 처리하고는 있지만, Redis는 다양한 데이터 구조를 제공하고 있다는 점에서 List, Hash, Set 등 데이터 구조에 따라 사용하는 명령어도 다르다. 이는 추후 Redis 사용법에 자세히 다룰 예정이다.
Redis의 캐싱 전략
Redis는 메모리 기반의 빠른 읽기/쓰기 처리 능력을 가지고 있다. 그래서인지 Radis는 캐시로 자주 활용되고 있다.
(캐시: 자주 사용되는 데이터를 임시로 저장하여, 원래 데이터를 저장하고 있는 곳(예: DB 또는 원본 서버)에 대한 접근을 줄이고 응답 속도를 향상시키는 기술) 그렇다면 Radis는 어떻게 캐싱으로 활용할 수 있을까?
Look Aside (= Lazy Loading)
캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 전략이다.
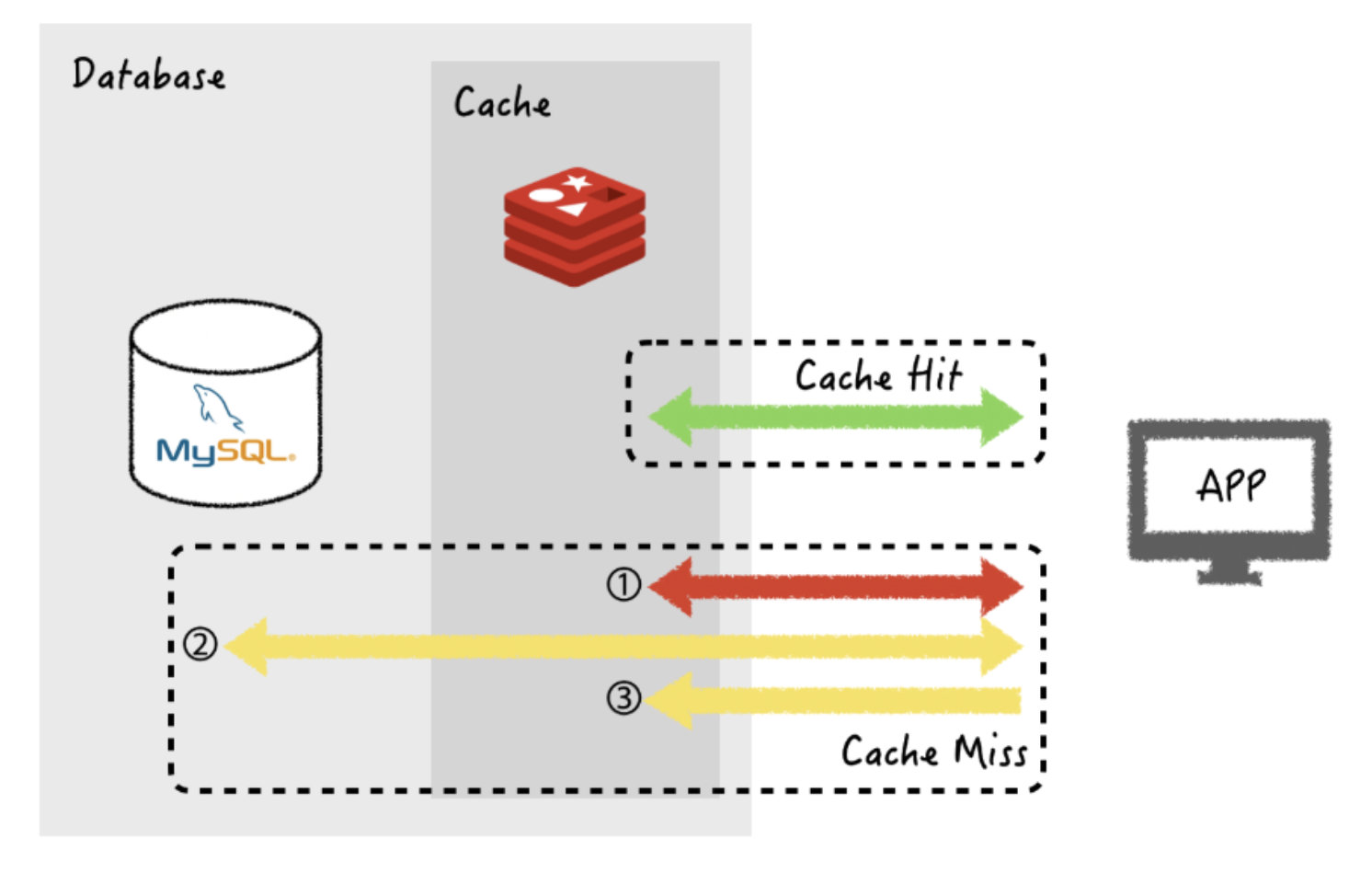
- 데이터 가져오는 요청이 왔다.
- Redis에 먼저 요청한다. 있으면 해당 데이터 반환, 끝
- 없으면 DB에 데이터 요청
- 해당 데이터를 Redis에 저장
이 전략은 실제로 사용되는 데이터만 캐시에 저장되고, 레디스의 장애가 어플리케이션에 치명적인 영향을 주지 않는 장점이 있다. 그러나 캐시에 없는 데이터를 가져올 때 느리고, 캐시에 있는 데이터가 항상 최신임을 보장할 수 없는 단점이 존재한다.
(잠시만… 이 형태… 뭔가 익숙하지 않는가? 맞다. JPA를 공부했다면, JPA의 영속성 컨텍스트에서 1차 캐싱을 이용해 데이터를 가져오는 과정과 유사하다!)
Write-through
데이터를 데이터베이스에 작성할 때마다 캐시에 데이터를 추가하거나 업데이트하는 전략이다.
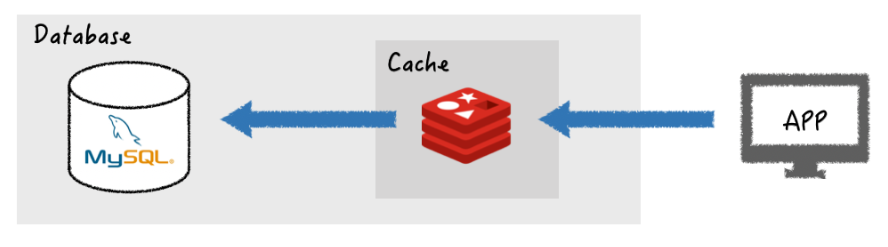
이전 Look Aside에서 지적되는 최신 형상 유지 문제점을 해결해주는 방법이다. 다만, 쓰지 않는 데이터도 캐시에 저장되기 때문에 리소스가 낭비되고 지연 시간도 증가되는 방식이라는 단점이 존재한다. 이에 대하여 TTL(Time-To-Live)기능을 활용하여 사용하지 않는 오래된 데이터를 삭제하여 해결할 수 있다.
Redis 사용 예제
- 유명 인플루언서의 게시글에 좋아요 클릭이 늘어날 때
- 기존 RDBMS: 누가 좋아하는지 그리고 조회수가 갱신됨으로써 insert와 update가 자주 발생 => 성능 저하 발생
- Redis: key가 게시글이고, value가 좋아요 누른 회원들의 set인 구조로 관리하여 그저 set에다 회원ID를 추가만 하면 됨
- 최근 검색 목록 표시
- 기존 RDBMS: SQL로 조회 => 잔 작업(중복 제거, 개수 파악, 오래된 검색어 삭제)
- Redis: sorted set으로 이미 정렬된 값을 가져오기
결론
Redis는 NoSQL 기술의 고성능 메모리 기반의 Key-Value 구조의 데이터베이스이다. Redis의 데이터 구조 형식은 다양하게 존재하고 있어, 개발의 도움과 폭넓은 활용에 유용하며, 주로 캐시로 자주 활용이 된다.
이제 어떻게 사용하는 지는 다음 포스트에 알아본다.
